We present a model for predicting the Quality of Experience (QoE) of German machinegenerated text from Automatic Text Summarization (ATS) and Machine Translation (MT). Based on previously established quality dimensions, we fine-tuned BERT for ATS and ELECTRA for MT, which performed best per task. Adding linguistic features further improved accuracy. For ATS, BERT excelled as a multitarget regressor; for MT, separate ELECTRA models performed best. Our results show that combining linguistic features with language models enables robust QoE prediction.
@inproceedings{pham-etal-2025-modeling,title={Modeling Quality of Experience in {G}erman Automatic Text Summarization and Machine Translation},author={Pham, Dinh Nam and Macketanz, Vivien and Manakhimova, Shushen and M{\"o}ller, Sebastian},booktitle={Proceedings of the 21st Conference on Natural Language Processing (KONVENS 2025): Workshops},month=sep,year={2025},address={Hannover, Germany},publisher={HsH Applied Academics},url={https://aclanthology.org/2025.konvens-2.12/},pages={169--175},}
×
The Importance of Facial Features in Vision-based Sign Language Recognition: Eyes, Mouth or Full Face?
Dinh Nam Pham, and Eleftherios Avramidis
In ACM International Conference on Intelligent Virtual Agents (IVA Adjunct ’25). 9th International Workshop on Sign Language Translation and Avatar Technology (SLTAT 2025)
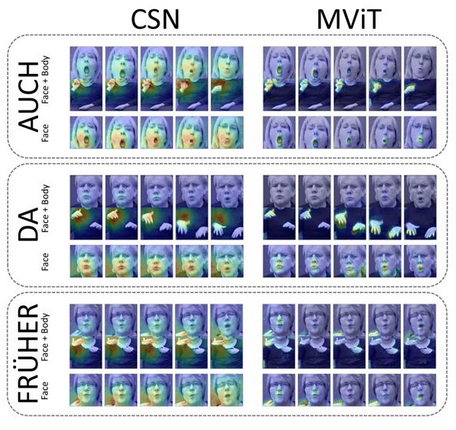
Non-manual facial features play a crucial role in sign language communication, yet their importance in automatic sign language recognition (ASLR) remains underexplored. While prior studies have shown that incorporating facial features can improve recognition, related work often relies on hand-crafted feature extraction and fails to go beyond the comparison of manual features versus the combination of manual and facial features. In this work, we systematically investigate the contribution of distinct facial regions eyes, mouth, and full face using two different deep learning models (a CNN-based model and a transformer-based model) trained on an SLR dataset of isolated signs with randomly selected classes. Through quantitative performance and qualitative saliency map evaluation, we reveal that the mouth is the most important non-manual facial feature, significantly improving accuracy. Our findings highlight the necessity of incorporating facial features in ASLR.
@inproceedings{pham2025sltat,author={Pham, Dinh Nam and Avramidis, Eleftherios},title={The Importance of Facial Features in Vision-based Sign Language Recognition: Eyes, Mouth or Full Face?},booktitle={ACM International Conference on Intelligent Virtual Agents (IVA Adjunct ’25). 9th International Workshop on Sign Language Translation and Avatar Technology (SLTAT 2025)},year={2025},month=sep,publisher={ACM},isbn={979-8-4007-1996-7/25/09},doi={doi.org/10.1145/3742886.3756718},}
×
Transfer Learning from Visual Speech Recognition to Mouthing Recognition in German Sign Language
Dinh Nam Pham, and Eleftherios Avramidis
In 2025 IEEE 19th International Conference on Automatic Face and Gesture Recognition (FG)
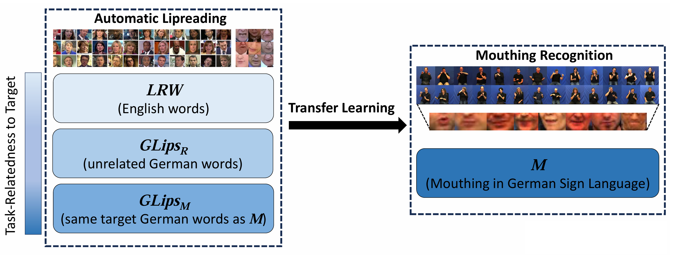
Sign Language Recognition (SLR) systems primarily focus on manual gestures, but non-manual features such as mouth movements, specifically mouthing, provide valuable linguistic information. This work directly classifies mouthing instances to their corresponding words in the spoken language while exploring the potential of transfer learning from Visual Speech Recognition (VSR) to mouthing recognition in German Sign Language. We leverage three VSR datasets: one in English, one in German with unrelated words and one in German containing the same target words as the mouthing dataset, to investigate the impact of task similarity in this setting. Our results demonstrate that multi-task learning improves both mouthing recognition and VSR accuracy as well as model robustness, suggesting that mouthing recognition should be treated as a distinct but related task to VSR. This research contributes to the field of SLR by proposing knowledge transfer from VSR to SLR datasets with limited mouthing annotations.
@inproceedings{pham2025vsrmouthing,author={Pham, Dinh Nam and Avramidis, Eleftherios},booktitle={2025 IEEE 19th International Conference on Automatic Face and Gesture Recognition (FG)},title={Transfer Learning from Visual Speech Recognition to Mouthing Recognition in German Sign Language},year={2025},pages={1-6},doi={10.1109/FG61629.2025.11099322},}
2023
×
Disambiguating Signs: Deep Learning-based Gloss-level Classification for German Sign Language by Utilizing Mouth Actions
Dinh Nam Pham, Vera Czehmann, and Eleftherios Avramidis
In Proceedings of the 31st European Symposium on Artificial Neural Networks, Computational Intelligence, and Machine Learning (ESANN 2023)
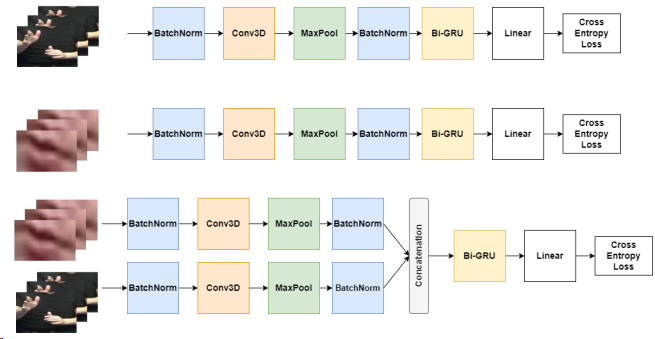
Despite the importance of mouth actions in Sign Languages, previous work on Automatic Sign Language Recognition (ASLR) has limited use of the mouth area. Disambiguation of homonyms is one of the functions of mouth actions, making them essential for tasks involving ambiguous hand signs. To measure their importance for ASLR, we trained a classifier to recognize ambiguous hand signs. We compared three models which use the upper body/hands area, the mouth, and both combined as input. We found that the addition of the mouth area in the model resulted in the best accuracy, giving an improvement of 7.2% and 4.7% on the validation and test set, while allowing disambiguation of the hand signs for most of the cases. In cases where the disambiguation failed, it was observed that the signers in the video samples occasionally didn’t perform mouthings. In a few cases, the mouthing was enough to achieve full disambiguation of the signs. We conclude that further investigation on the modelling of the mouth region can be beneficial of future ASLR systems.
@inproceedings{phamd2023disambiguating,title={Disambiguating Signs: Deep Learning-based Gloss-level Classification for German Sign Language by Utilizing Mouth Actions},author={Pham, Dinh Nam and Czehmann, Vera and Avramidis, Eleftherios},booktitle={Proceedings of the 31st European Symposium on Artificial Neural Networks, Computational Intelligence, and Machine Learning (ESANN 2023)},year={2023},pages={595--600},publisher={i6doc.com publ.},isbn={978-2-87587-088-9},doi={10.14428/esann/2023.ES2023-168},}
2022
×
Entwicklung und Evaluation eines Deep-Learning-Algorithmus für die Worterkennung aus Lippenbewegungen für die deutsche Sprache
Dinh Nam Pham, and Torsten Rahne
HNO, 2022
⭐Best Poster Award @ DGA 2022 (German Society of Audiology)
When reading lips, many people benefit from additional visual information from the lip movements of the speaker, which is, however, very error prone. Algorithms for lip reading with artificial intelligence based on artificial neural networks significantly improve word recognition but are not available for the German language. A total of 1806 videoclips with only one German-speaking person each were selected, split into word segments, and assigned to word classes using speech-recognition software. In 38,391 video segments with 32 speakers, 18 polysyllabic, visually distinguishable words were used to train and validate a neural network. The 3D Convolutional Neural Network and Gated Recurrent Units models and a combination of both models (GRUConv) were compared, as were different image sections and color spaces of the videos. The accuracy was determined in 5000 training epochs. Comparison of the color spaces did not reveal any relevant different correct classification rates in the range from 69% to 72%. With a cut to the lips, a significantly higher accuracy of 70% was achieved than when cut to the entire speaker’s face (34%). With the GRUConv model, the maximum accuracies were 87% with known speakers and 63% in the validation with unknown speakers. The neural network for lip reading, which was first developed for the German language, shows a very high level of accuracy, comparable to English-language algorithms. It works with unknown speakers as well and can be generalized with more word classes.
@article{pham2022dev,title={Entwicklung und Evaluation eines Deep-Learning-Algorithmus f{\"u}r die Worterkennung aus Lippenbewegungen f{\"u}r die deutsche Sprache},author={Pham, Dinh Nam and Rahne, Torsten},journal={HNO},volume={70},number={6},pages={456--465},year={2022},doi={10.1007/s00106-021-01143-9},note={},}